Cloud Disaster Recovery a strategy for restoring cloud workloads after failures by recovering the data, configurations, permissions, and dependencies needed to run again and support Business Continuity. It needs to support recovery time and recovery point targets. And, setting up backups alone won’t help you. ControlMonkey approaches this through infrastructure recovery using Terraform based snapshots, rollback to known good configurations, and visibility into recovery coverage.
TL;DR
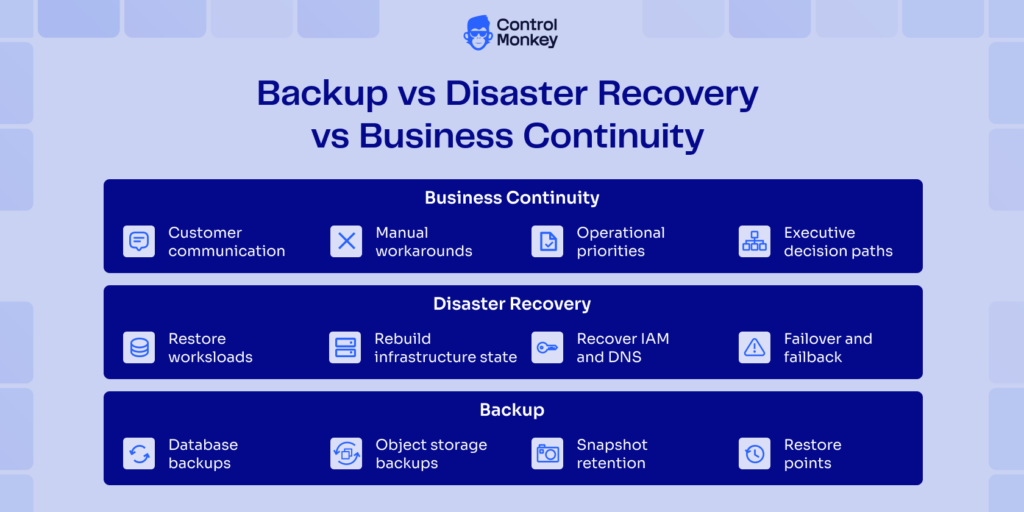
- In practical terms, cloud disaster recovery means restoring a cloud workload after a failure so it can return to service. That includes data, infrastructure configuration, identity and access settings, network dependencies, and service connections.
- How it works: Cloud DR uses backups, snapshots, replication, configuration recovery, and failover procedures. It also depends on restoring services in the right order and validating DNS, IAM, routing, and related dependencies.
- Why it matters: Cloud backup and disaster recovery are connected, but backups alone do not guarantee recovery.
- A restore can still fail if critical settings or external dependencies are missing, outdated, or misconfigured. AWS also distinguishes backup-and-restore from faster recovery strategies because they involve different tradeoffs in cost, complexity, RTO, and RPO.
- Why testing matters: Recovery plans need regular testing and validation. Without it, teams often find gaps only during an incident.
- ControlMonkey focuses on infrastructure and configuration recovery through Terraform-based snapshots, rollback to known-good states, and recovery coverage across cloud platforms and selected control-layer services.
Cloud Disaster Recovery is the process of restoring a cloud workload after a failure so it can run again. It covers more than data recovery. It also includes the infrastructure around the workload, such as IAM, DNS, networking, and service configuration. If those parts come back in the wrong state, the application can still stay down and extend Downtime even when the data is intact.
AWS frames disaster recovery around targets such as Recovery Time Objective (RTO) and Recovery Point Objective (RPO), not just around having backups. NIST also treats recovery as an operational capability that depends on documented procedures, testing, backup, and system recovery.
Why Cloud-Based Recovery Is Essential
The old way of thinking about recovery was pretty simple. A backup site, extra hardware, and a runbook. It’s often a routine practice, once a year, to train and to validate if the team could handle the disruption. That model alone does not work with modern disaster recovery in Cloud Computing environments, where identity, networking, and control-plane dependencies can delay recovery even when data survives.
CISA ransomware guidance still emphasizes backup integrity and incident readiness, but the recovery path now goes beyond files and databases. Service identities, control plane access, cloud networking, and other infrastructure dependencies that are not part of the main application path can still block recovery.
Then there is a newer problem. AI agents and automation accounts that are too permissive can move quickly, use too many resources, and make harmful changes that look valid until someone notices the damage. OWASP guidance on AI and automation risks highlights issues like excessive permissions, broken access control, and unsafe tool usage. Microsoft’s enterprise guidance also focuses on identity, governance, and control in these systems. This matters because a recovery event does not always start with an outage. It can start with a bad configuration or an automated action at scale.
Learn from AWS Disaster Recovery Experts: 4 Hidden Gaps in Your DR Plan
Join AWS resilience experts and ControlMonkey to learn the hidden gaps that make cloud disaster recovery fail at scale – and how to fix them before the next outage.
So, disaster recovery in the cloud is no longer just a platform concern. It connects directly to business risk, audit, and resilience. ControlMonkey cloud disaster recovery fits this approach because it treats recovery as both a governance and configuration problem, not just a backup exercise.
Key points:
- Recovery now includes identity, networking, and control plane dependencies.
- Failures can start from misconfiguration, not just outages.
- Visibility into what is recoverable is critical.
How Cloud DR Works
Most diagrams of recovery plans look neat. It typically includes state capture, dependency mapping, testing, and failover logic. The specifics depend on the workload, but the general shape remains the same, where it needs to protect resources, restore them in the right order, and ensure the recovered environment is stable and usable.
Replication, snapshotting, and backups (choose the right mix)
Backups, snapshots, and replication solve different problems. Teams run into trouble when they treat them as interchangeable. Backups are usually the simplest option. They protect data, store it in a much safer place and allow restoration later. Snapshots capture the state of a resource at a specific time. Replication can improve availability, even amidst partial failures, but it increases cost and operational complexity. AWS categorizes the use of these techniques as part of different disaster recovery strategies, such as backup-and-restore, warm standby, and multi-site active setups.
| Method | Main purpose | Recovery speed | Cost | Ops complexity | Best fit |
|---|---|---|---|---|---|
| Backup | Durable copy for later restore | Slowest | Low | Low | Long-term retention, basic restore |
| Snapshot | Point-in-time state capture | Medium | Medium | Medium | Fast rollback, resource-level restore |
| Replication | Keep secondary copy close to current state | Fastest | Highest | Highest | Tight RTO/RPO workloads |
This is where cloud backup disaster recovery is often misunderstood, because teams protect the data and assume the workload itself is fully recoverable.
As environments scale across accounts, regions, and unmanaged infrastructure, recovery starts depending on the memory and skills of the team. That does not consistently hold up under pressure. The more distributed the environment becomes, the more recovery depends on whether configuration state was preserved with the same care as the data layer.
ControlMonkey’s disaster recovery solution targets this gap. It prioritizes active Terraform-based infrastructure snapshots, allows rollback to known good infrastructure states, and provides recovery visibility across IAM, DNS, and selected third party configurations. This complements data recovery options available in the cloud rather than replacing it.
Verification and testing (prove recoverability)
NIST contingency planning guidance treats testing as a required part of maintaining recovery readiness. AWS makes a similar point in their well architected framework. If you want to rely on a recovery strategy, you need to test it regularly.
A cleaner approach is restoring into separate environments and measuring outcomes. Rebuild the network path, validate the secrets chain, make sure workloads can start properly, and confirm traffic really flows where expected. Testing becomes useful when it starts resembling the event you are trying to survive. That is when gaps show up.
| Gap found during testing | What usually breaks | Recovery impact | Typical fix |
|---|---|---|---|
| Incorrect restore order | App starts before dependencies are ready | Medium to High | Add orchestration steps and checks |
| Missing dependencies | Secret store, queue, DNS, or IAM path is missing | High | Expand dependency map |
| Outdated infrastructure code | Restored state does not match live environment | High | Reconcile code and drift |
| Permissions drift | Recovery account cannot perform required actions | High | Review roles, policies, trust paths |
Testing also produces what leadership and auditors actually need, measuring recovery times, known gaps, and verified coverage.
Failover and failback orchestration (recover in the right order)
Failover execution could go wrong due to many reasons. For example, in a restore operation, DNS may update faster than the stack of dependencies that it needs. Someone fixes a service, but not the policy or secret that it needed. These are common ways that things go wrong, and they are exactly why DR planning needs to take dependencies into account. AWS also stresses the importance of coordinating recovery across components and taking into account their dependencies.
That is a big part of how DR in cloud actually works. You are not bringing the environment back all at once. You are restoring layers that depend on each other, and even small mistakes in the order can turn a short outage into a long one.
Failback is usually even worse. The recovery side has already changed by the time the main path is ready again. The data moved. There were emergency fixes. Permissions were changed under pressure. To return cleanly, you need to figure out what the new source of truth is and get back in sync without causing another problem. AWS says that failback is especially hard because data stores have to be restored and kept in sync with the recovery side that was running during the event.
Teams often plan the move out of the incident more carefully than the move back, even though failback is where hidden drift and emergency shortcuts tend to surface. That’s why failback needs to be part of cloud DR planning from the beginning, not as an afterthought. The recovery event is only halfway over when the system is back online. The harder part is getting back to a stable, controlled state without bringing shortcuts from the incident into production.
Cloud DR vs. Traditional DR
Traditional DR was based on duplication. Redundant hardware, facilities, and manual recovery processes. Cloud recovery changes that model. Capacity becomes flexible, testing becomes easier, and automation handles repeated tasks. The main tradeoff is that dynamic environments introduce drift, which becomes a major recovery risk. A well designed cloud DR model reduces reliance on memory and improvisation.
| Area | Traditional DR | Cloud DR |
|---|---|---|
| Infrastructure model | Duplicate hardware and facilities | Elastic cloud capacity |
| Recovery work | Heavier manual procedures | More automation and orchestration |
| Testing cadence | Often infrequent | Easier to run more often |
| Drift risk | Lower infrastructure churn, slower change | Higher change velocity, more drift risk |
| Cost model | High fixed cost | More variable operating cost |
| Restore scope | Systems and data center assets | Data, infra config, identity, networking, control plane |
ControlMonkey Solutions for Cloud DR
ControlMonkey helps with configuration recovery in AWS, Azure, GCP, Cloudflare, Okta, and some third party platforms.
That matters because configuration outages happen a lot and are often more complex than recovering data from backups. A change to an IAM policy, a deletion of a DNS record, a bad route, a missing edge setting, a configuration drift event, or a rushed manual fix can all break production without touching the main dataset.
If your recovery model only thinks about restoring data, you’ll have to rebuild the rest of it under pressure. It’s not just about governance to see unmanaged resources and code coverage. It is a necessity for recovery.
Cloud DR Use Cases and Compliance Requirements
When a team has to prove restore coverage, recovery timing, control ownership, and audit evidence, it needs to be evaluated against standard norms.
The question is no longer “Is it possible for us to recover?” It turns into “what do you want to get back, from where, by whom, and with what proof?” NIST’s advice on contingency planning pushes in that direction by focusing on recovery procedures, testing, ownership, and validation.
HoneyBook is a good example of a SaaS. According to ControlMonkey, HoneyBook cut its migration project by 80%. That fits with the bigger DR problem, where traditional backup tools don’t fully handle infrastructure settings like routing, edge configuration, and other dependencies at the environment level that can make recovery harder on a large scale. Drift happens when things grow, and it slowly makes it harder to recover.
If your infrastructure is growing, drift is already making recovery harder than it should be.
👉 See how HoneyBook reduced migration time by 80% and improved recovery readiness
Compliance changes what teams have to prove during recovery. It is not enough to say backups exist. Teams need tested restore steps, realistic recovery targets, and evidence that critical infrastructure can return in a controlled state. For the business, that means lower downtime risk, less manual recovery work, and better audit readiness.
| Customer | Why cloud DR mattered | Business / ROI impact |
|---|---|---|
| HoneyBook | Fast growth increased drift and made infrastructure recovery harder to trust | Reduced migration effort, better recovery readiness, less manual recovery work |
| Block | Large cloud estate, more controls, and more operational complexity | Lower operational risk, stronger compliance posture, better control at scale |
| Rapyd | Fintech environment with audit pressure and recovery risk | Better audit readiness, lower risk from manual changes, stronger recovery controls |
Cloud disaster recovery gets harder when infrastructure grows outside clean IaC coverage. Data may come back, but IAM, DNS, routing, and other configuration dependencies can still delay recovery. That is where ControlMonkey fits more naturally, by helping teams recover known-good infrastructure state, improve drift visibility, and build audit-ready recovery processes into the same workflow.

A 30-min meeting will save your team 1000s of hours
A 30-min meeting will save your team 1000s of hours
Author