Every major enterprise has data backups. Snapshots, replicas, ransomware protection — none of that is new. What is new is how often those same enterprises still go dark when something breaks in the network control plane.
And when users can’t reach your systems, your backups don’t matter.
Uptime is no longer a data problem. It’s a configuration problem.
Most resilience strategies still stop at the data layer. They treat “we can restore the database” as the finish line. In 2026, that’s not resilience. That’s a partial plan in a world that punishes partial plans.
Resilience Started with Data – and Downtime Got Expensive
For years, disaster recovery was defined by data. Lose a database, restore from backup, measure yourself on RTO and RPO. As long as the information came back within the agreed window, you were doing your job.
That model made sense when systems were simpler and the disaster radius of a failure was smaller.
Today, the cost of downtime is higher, the dependencies are more complex, and the and even the board expectations are close to zero tolerance. You can meet your recovery objectives on paper and still be losing customers every minute.
The irony is that many organizations have never been better at protecting their data. Ransomware playbooks are mature. Backup strategies are sophisticated. Board reports are full of green checks next to “data protection.” Yet in real incidents, the question is often not “did we lose data?” but “When can we be back up and running?”
The Other Half of the Outage
Modern outages start with a change, a misconfiguration, or a chain reaction somewhere in the path between your users and your applications. A poisoned DNS record, a broken routing rule, a bad CDN deployment, or a firewall policy pushed at the wrong tim – none of these touch the data directly, but all of them can take you completely offline.
In those moments, your applications are still running. Your databases are still healthy. Your observability tools may even show everything “green” inside the core. But from the outside, your business has been hurt. Customers care that they can’t log in or buy or interact.
The gap is simple to describe and hard to fix: data-centric resilience assumes the main risk is loss of information. In reality, one of the biggest risks is loss of reachability. That lives in the network control plane.
The Missing Layer in DR: Network Configuration
Routing rules, DNS records, CDN configurations, firewall policies, edge control-plane settings – this is the part of your environment that decides what traffic is allowed in, where it goes, and how it’s treated along the way. It is just as critical as the data and the application, but it is rarely treated with the same discipline.
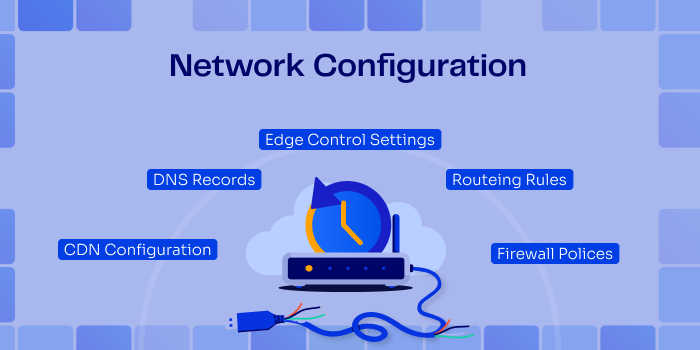
In practice, these configurations are spread across vendors and teams. Some live in Terraform, some in platform UIs, some in CLI scripts, and some only in someone’s memory of “how we set it up last time.”
They change frequently as you optimize performance, add regions, tighten security, or respond to incidents. Yet they are not consistently versioned, tested, or included in formal DR exercises.
When a serious incident hits that layer, recovery often looks like archaeology. Teams dig through old exports and screenshots, scroll back through Slack threads, and try to reconstruct what “good” looked like. That is not a recovery strategy. It’s guesswork under pressure.
And guesswork is always slow.
Cyber Resilience in 2026: Data, Infrastructure, Network Control Plane
If you look at how your business actually runs in the cloud, there are three layers you need to protect. In reality, you’re protecting three layers:
- Data – the information itself. Where Rubrik, Zerto, Veamo and more protect you
- Infrastructure configuration – the cloud resources, identities, and policies that run your workloads.
- Network control plane – DNS, CDN, routing, and edge policies that make those workloads reachable.

Most enterprises have invested heavily in the first layer and have made real progress on the second through Infrastructure-as-Code. The third layer remains dangerously exposed. It is assumed to be “stable” until it isn’t, and when it fails, it can neutralize every other investment you have made in resilience.
True cyber resilience in 2026 means treating the network control plane as a first-class recovery domain. Not an afterthought. Not something you fix with hero work during an incident. If users can’t route to you, a “successful” data restore is still a complete business failure.
ControlMonkey Is Extending DR to the Network layer
ControlMonkey has already shown what happens when you bring order to infrastructure recovery. Daily snapshots of your cloud configuration. Terraform-native code generation. One-click rollback to the last good state. Infrastructure stops being a mystery and becomes something you can restore quickly and predictably.
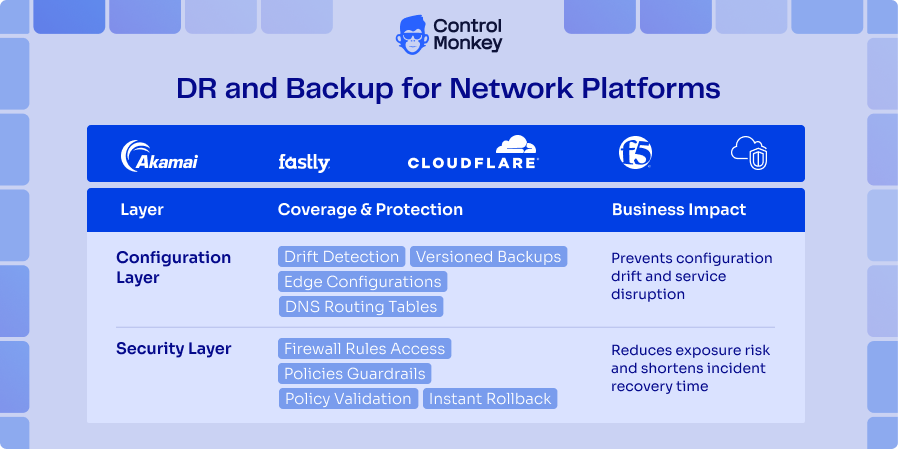
We are now extending that same principle to the network layer. DNS zones and records, CDN and edge configurations, routing decisions, and firewall and security policies are all brought under the same discipline. Instead of being scattered across different vendor consoles and half-documented processes, they are discovered, captured, and versioned in a format your team already understands.
With this approach, Akamai, F5, Fastly, Cloudflare and other supported configurations aren’t just settings hidden in vendor consoles. They become versioned code in your own repo that your team can read, review and roll back. The network control plane becomes a normal part of your disaster recovery process, not a gap you only notice during an incident.
Version Control Determines Recoverability
Fast, reliable recovery is not about having the smartest people in the room. It is about knowing exactly what your last known good state was, having confidence that it is correct, and being able to move back to it without improvisation. That is what version control gives you.
You don’t get fast recovery by accident. You get it when:
- You know the last known good state.
- You know it isn’t corrupted.
- You know how it changed over time.
- You can see where it drifted.
- You can restore it automatically.
Infrastructure-as-Code brought that to cloud resources. You can see when a change was made, who approved it, what it did, and how to revert it. Extending that same capability to the network control plane means you are no longer depending on tribal knowledge and vendor UIs when something breaks. You have a clear history, a clear diff, and a clear path back.
When a routing rule, DNS configuration, or edge policy goes wrong, you don’t start from a blank screen. You restore a known good state. Not slowly, by hand, but as part of an automated workflow your team already uses every day.
Will Your Network Be Ready When It Matters?
Most CIOs and CISOs can answer a simple question about data: if we lost a database, could we restore it within our RTO and RPO? The honest answer is usually yes. They have spent years making sure of it.
The harder question is about the network control plane. If your DNS, routing, and edge configurations were wiped or corrupted tomorrow – across providers – how quickly and accurately could you rebuild them? Would you be confident in the answer, or would you be hoping it works out because “we have good people”?
In the next wave of incidents, your customers will not be impressed that the data was safe if they could not reach your service when it counted. They do not experience your RPO. They experience your downtime.
Rethink your network disaster recovery strategy
When the network fails, data backups don’t matter. let’s rethink your network disaster recovery strategy – Get today free DR risk assessment

A 30-min meeting will save your team 1000s of hours
A 30-min meeting will save your team 1000s of hours
Author