Everyone trusts observability in a disaster.
No one protects it.
During a production incident, the first system engineers open isn’t backup storage or failover tooling. It’s the dashboard: Datadog, Dynatrace, Grafana, New Relic etc…
And that makes sense, they want to check what’s wrong with their system, the metrics, the trends, maybe an alert that popped and they missed.
That’s where your production source of truth is supposed to be.
But what happens when that layer is wrong, broken, or gone entirely?
The Missing Layer No One Accounts For
Most disaster recovery strategies focus on what feels essential – databases, storage, and infrastructure. More mature teams have started extending that thinking into infrastructure as code and even network configurations.
But there’s a layer sitting on top of all of it that gets ignored: observability configuration.
Dashboards, alert rules, monitors, and escalation policies are not just visual artifacts.
They encode years of operational logic. They define what gets detected, what gets ignored, and how incidents are handled under pressure. Yet in most environments, this layer is created manually, evolves organically, and is almost never versioned or recoverable.
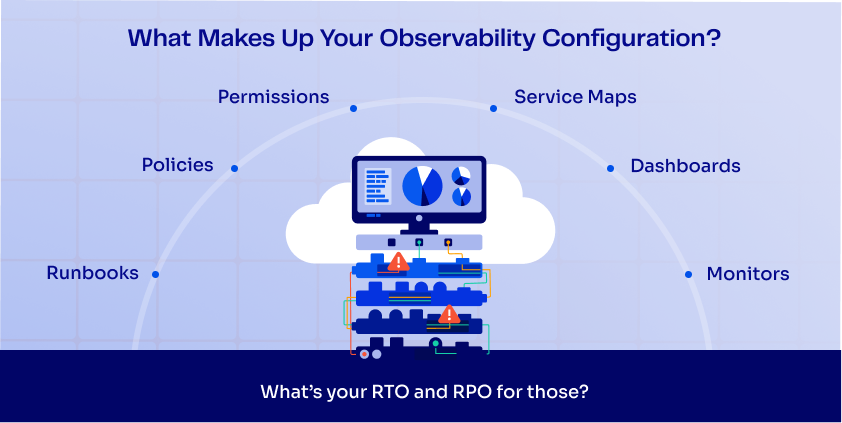
What could go wrong with your observability layer?
There are the few traditional threat vectors:
- Ransomware
- Malicious actor
- Honest mistake of one of your employees
But lately we see a new emerging threat vector – you probably heard about this thing called AI.
Right now, your employees in your organization are running AI agents, with MCP connectors, in different flavours for multiple tasks.
AI agents are not deterministic by design. And employees might use them with admin permissions.
What happens when you put together strong permissions with hallucination? You’re right – bad things.
What are the chances that right now in your organization, an employee is using an AI agent to create and modify Datadog dashboards? How long will it take till the AI agent will make a mistake and wrongly update or delete a resource?
I think you know the answer – and this is what CIOs and CISOs I talk to are really worried about.
When This Layer Breaks, Everything Slows Down
The failure mode here is subtle, but the impact is immediate.
- A dashboard gets overwritten.
- An alert stops firing.
- A monitor threshold is changed and no one notices.
- An AI agent “optimizes” rules and removes critical signals.
Once that happens, you’re already lagging behind.
It’s just a matter of time till you’ll miss your next production outage.
Assuming you find out that your observability layer got compromised – what are your option?
Engineers start second-guessing what they see. They will probably try and rebuild dashboards manually, from their memory. They dig through logs without clear direction.

Extending Disaster Recovery to Observability
This is where the current model breaks. Modern cloud environments are no longer just infrastructure and data – they are also the 3rd party tools or the ‘satellites’ that support your production SLA.. This is the gap ControlMonkey addresses.
In practice, ControlMonkey automatically captures daily snapshots of your observability configurations across platforms like Datadog, New Relic, Dynatrace, Grafana Cloud, and Splunk. Dashboards, alert rules, monitors, and escalation policies are versioned and can be restored on demand, without manual reconstruction.
At the same time, ControlMonkey continuously tracks changes, detects drift, and provides a clear view of what is actually recoverable across the entire cloud control plane.
This isn’t about improving observability. It’s about ensuring it survives failure.
The Part of Disaster Recovery You Haven’t Tested
Most teams believe their disaster recovery plan is complete. Infrastructure can be redeployed, data can be restored, and systems can come back online.
But the system that tells you what’s happening during a failure is still unprotected.
So the question is simple: when the next incident happens, will your team be able to see clearly – or will they be rebuilding visibility while the system is already failing?
Rethink your network disaster recovery strategy
When the observability layers fails, data backups don’t matter. let’s rethink your disaster recovery strategy – Get today free DR risk assessment

A 30-min meeting will save your team 1000s of hours
A 30-min meeting will save your team 1000s of hours
Author