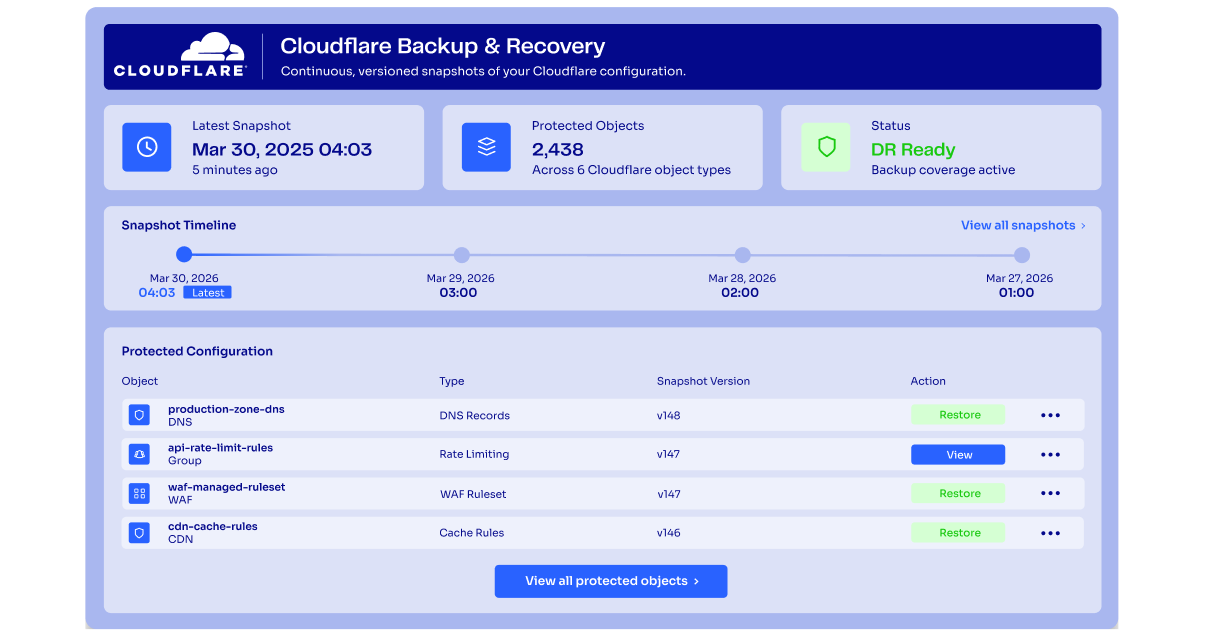
ControlMonkey automates Cloudflare backup and recovery, protecting DNS records, firewall rules, WAF policies, tunnels, and access configurations to strengthen cyber resilience.


































Book Intro Meeting
Discover How ControlMonkey will save Your team 1000s of hours.