To scale Terraform is essential for modern DevOps teams managing infrastructure across distributed environments. As physical boundaries no longer limit access to talent, organizations are using Terraform. This helps them manage teams around the world and improve cloud operations. By leveraging Infrastructure as Code (IaC), businesses can enhance collaboration, automate infrastructure management, and maintain consistency—regardless of where their teams are located.
Forming distributed DevOps teams is a natural choice to enhance business agility. This approach has numerous benefits—24/7 operations, cost efficiency, global talent access, and business continuity and resilience, to name a few.
However, when working as a distributed team, you can run into challenges such as: collaboration, maintaining consistency, change management, access control, versioning and implementing auditing across cloud infrastructure.
So, in this article, let’s explore how Terraform can be used to effectively manage large-scale cloud infrastructure with distributed DevOps teams.
How to Scale Terraform for Multi-Team Collaboration
Collaboration makes distributed DevOps possible and allows teams to operate at scale.
Collaborating on the infrastructure directly raises many concerns since there is no transparency on what changes other members are working on. The solution to this problem is to use Infrastructure as Code (IaC).
IaC is integral for collaboration, where multiple developers can contribute to improving the configurations. The syntax and structure of IaC depends on the IaC tool that you use. Terraform is a popular IaC tool, which is cloud-agnostic. Mastering Terraform allows teams to apply the same skills across projects involving infrastructure in different cloud platforms. Terraform provides the required features and functionalities that support collaboration among multiple users and teams.

Remote State Management to Scale Terraform at Scale
Terraform state contains details about the infrastructure it manages and its current status. It’s how Terraform keeps track of changes it needs to do to existing infrastructure. Every team member requires a copy of the state file to make changes to existing infrastructure. Terraform supports different state backends, such as AWS S3 or other cloud-agnostic solutions to store and share the state. Many remote backends offer state-locking mechanisms, which prevent concurrent modifications by multiple team members, ensuring infrastructure integrity.
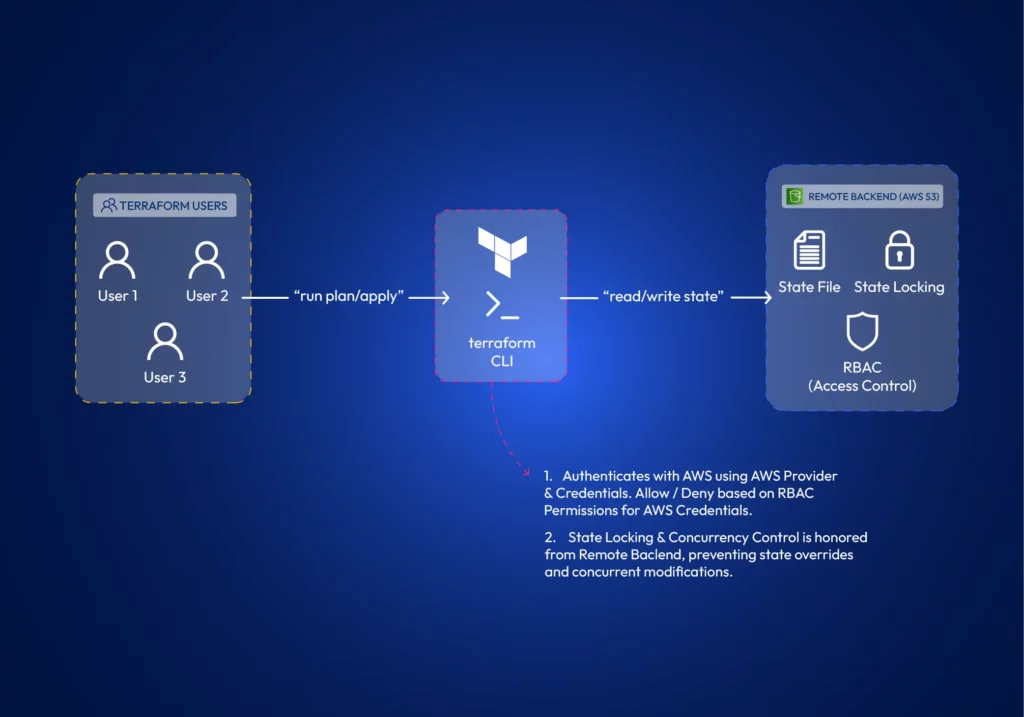
Workspaces (and Projects)
Workspaces allow teams to manage multiple isolated environments (such as development, staging, and production) within a single Terraform configuration. Teams can work on different environments in isolation. Terraform projects allow administrators to scope and assign workspace access to teams or developers. In larger environments, teams often use scoped workspaces and project-based access to isolate environments and assign permissions.
Declarative Syntax
What really distinguishes between developers is how they think and the logic they apply to solve a problem.
To print numbers from 1 to 5 in the console, a developer could use a for loop, a while loop, or just type the print command 5 times. Collaboration raises questions about consistency and standards.
Luckily, Terraform is declarative. You do not have to say “how”, but rather “what” to do. This is helpful for collaboration since the actual logic of deploying the resources is not a part of IaC. It is taken care of by Terraform.
Here is how you would define creating an AWS S3 bucket with Terraform;
resource "aws_s3_bucket" "data_lake" {
bucket = "controlmonkey-data-lake"
tags = {
Environment = "Production"
}
}Just to compare how it would be without Terraform, here is a shell script to do the same operation without Terraform;
#!/bin/bash
# Configure AWS CLI
aws configure set region us-west-2
# Check if bucket already exists
BUCKET_EXISTS=$(aws s3api head-bucket --bucket controlmonkey-data-lake 2>&1 || echo "not exists")
# Create bucket only if it doesn't exist
if [[ $BUCKET_EXISTS == *"not exists"* ]]; then
echo "Creating S3 bucket..."
aws s3api create-bucket \
--bucket controlmonkey-data-lake \
--region us-west-2 \
--create-bucket-configuration LocationConstraint=us-west-2
# Add tags to the bucket
aws s3api put-bucket-tagging \
--bucket controlmonkey-data-lake \
--tagging "TagSet=[{Key=Environment,Value=Production}]"
echo "Bucket created successfully"
else
echo "Bucket already exists, skipping creation"
fiA simpler code is generally better for collaboration.
Reusable Modules to Scale Terraform Consistently Across Environments
With Terraform, you can encapsulate common infrastructure patterns into modules. Teams can develop modules separately and reuse them to ensure they deploy infrastructure components in a consistent and compliant manner.
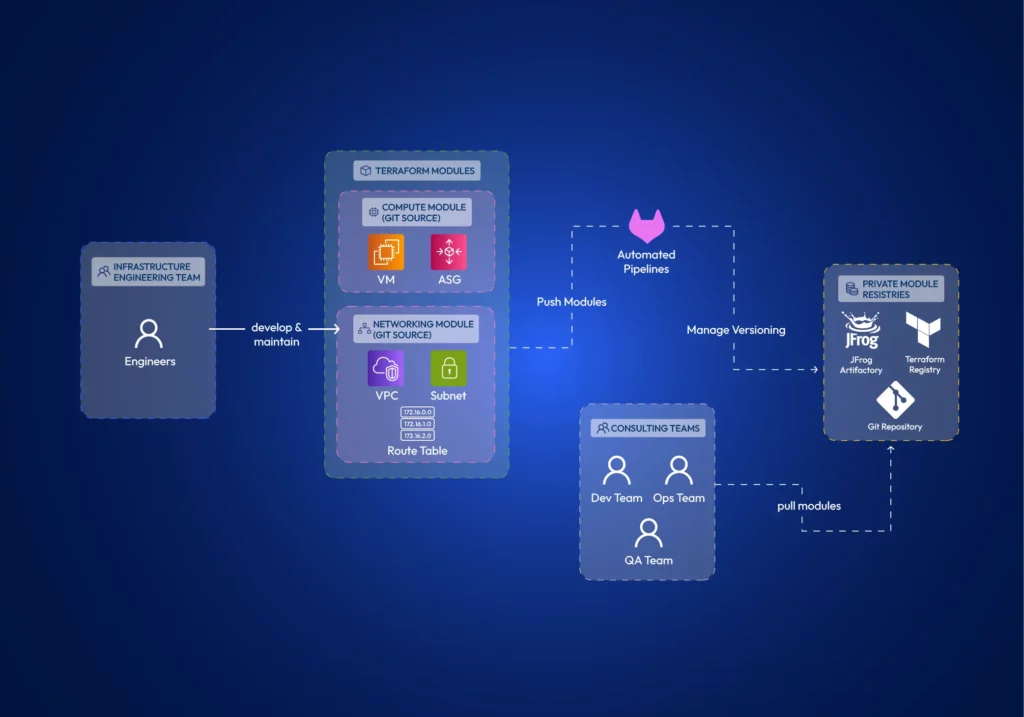
Terraform supports remotely hosting these modules in private registries such as JFrog Artifactory, Terraform Registry, or Git. Therefore, multiple teams can effectively utilize them.
5 Ways to Scale Terraform for Teams
We have already identified the Terraform features that allow collaboration. Let’s explore how to properly architect Terraform projects for effective collaboration across distributed teams.
Using identical Terraform versions across all teams & members.
The Terraform version should be an organizational policy. Using different terraform versions can cause several major issues;
- Terraform syntax might not be backward compatible between certain versions.
- Deprecated features might work in older versions but fail in newer ones.
- State-file changes. The internal state format can change between major versions, leading to state corruption or inability to read state files.
Another thing to watch out for is that the terraform core executable comes in both amd64 and arm formats. Terraform providers are architecture-specific binary plugins. A provider compiled for amd64 won’t work on ARM systems and vice versa. It’s best practice to install amd64 on both systems (You can install it on ARM systems using environment variable TFENV_ARCH ). Otherwise, some team members may be unable to use providers defined in the code if provider developers haven’t compiled them for their specific architecture.
Decomposed and Modular Infrastructure:
Using Terraform modules helps establish the principle of separation of concerns. Teams can develop Terraform modules in isolation. Terraform modules minimize dependencies between different parts of the system, reducing the potential impact of changes (the blast radius).
Granular access control is a theme when working with distributed teams. When you architect your modules, you need to be concerned about how you manage the module source code and how you publish modules. When developing module source code, it is best practice to have separate git repositories per each module. Distributed teams can focus on different modules. With this approach, you can granularly control the read-write permissions per repo. Further, suppose you use git as the module registry itself. In that case, having monolithic repos causes the whole git repository to be copied to the .terraform directory, regardless of whether you only refer to a single path (a module) within the repository.
The developed modules should be versioned and shared with the Distributed Teams. Terraform Registry or a compatible artifact registry can store Terraform modules so other teams can refer to them in their infrastructure configurations. Access controls can be implemented in registries as well.
Remote State & Environment Isolation Strategies
We have already discussed Terraform’s capabilities to store state remotely and its features such as state locking, versioning, and RBAC access to state. However, the Terraform state is also important in environment isolation.
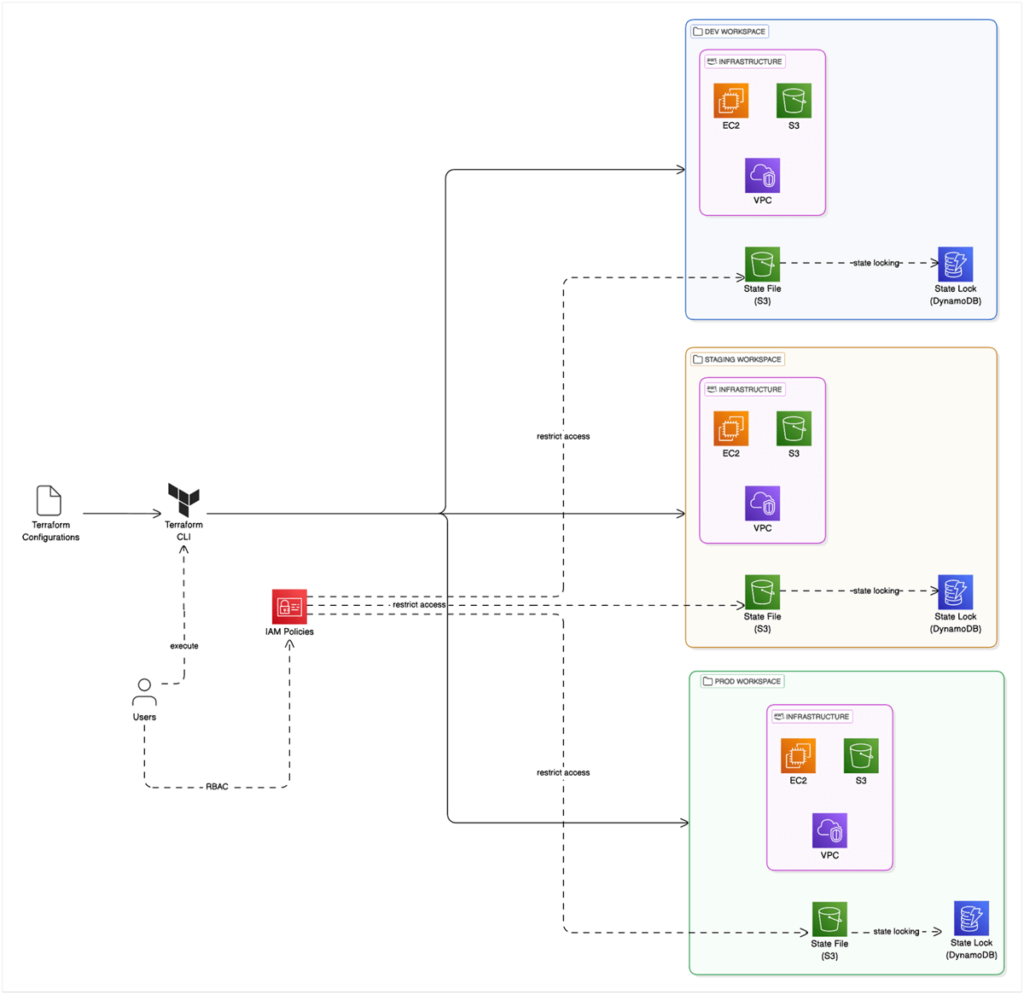
Teams can utilize Terraform workspaces to isolate environments. Terraform Workspaces automatically manages a separate state file per environment (Note: State files do not require distinct S3 buckets; instead, you can use different keys). In this example, we are using Terraform in AWS and leveraging IAM policies to control access to environments.
However, another approach is to use a directory structure that isolates environments.
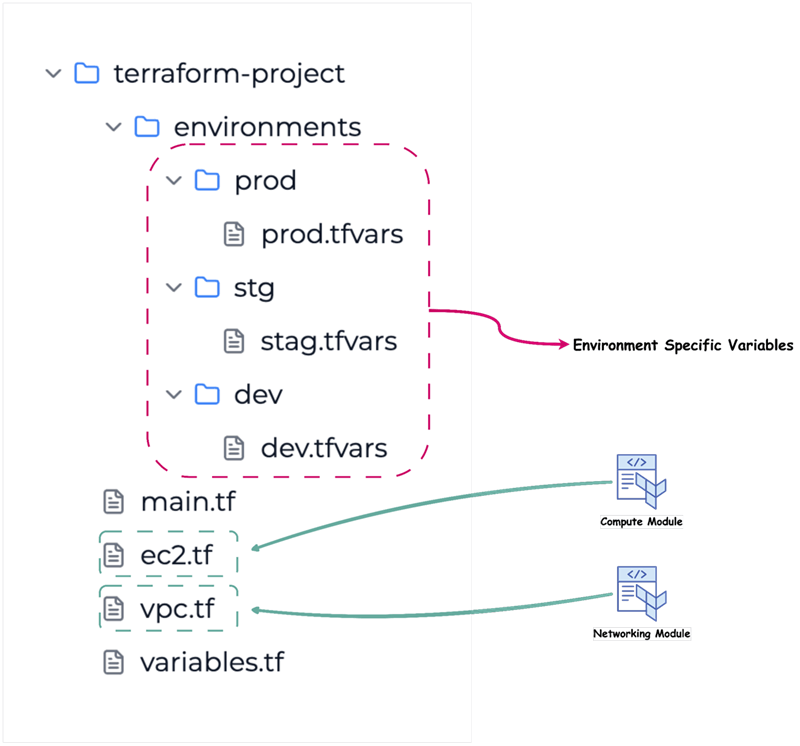
Workflow Organization for Teams
Workflow is essentially how the team or teams operate. When working as a distributed team, there should be a defined set of standards when using source control and changes. First, teams should use a branching strategy, such as GitFlow or GitHub Flow to manage different environments and features.
Another strategy for Terraform code is “trunk-based development”. This strategy suits better since infrastructure can have only one version deployed. Workflow should focus on facilitating code reviews, controlling the promotion of changes through the development lifecycle, and drift detection when infrastructure changes outside of your sources.
With trunk-based development, developers merge directly to the main branch after reviewing their code.
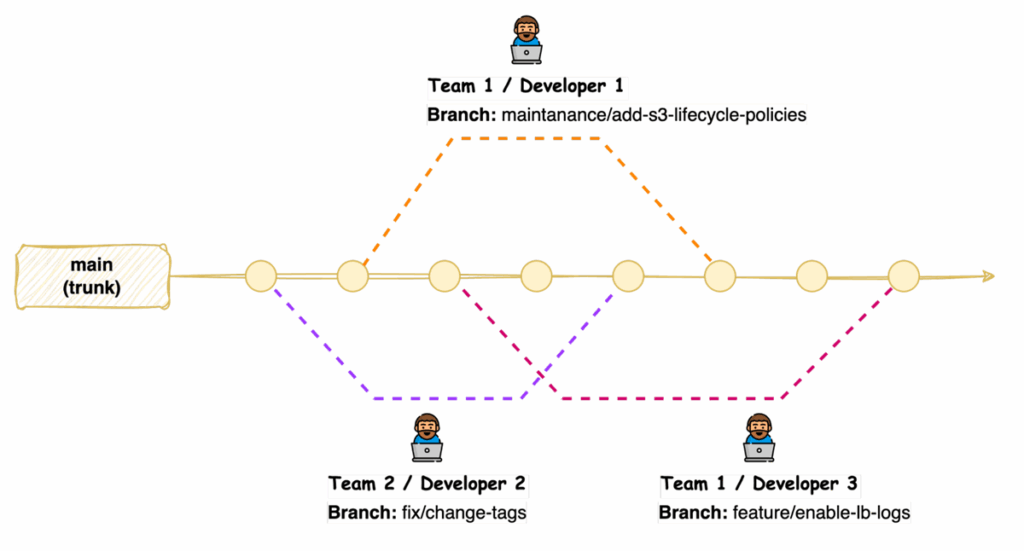
Distributed teams can benefit from implementing code review processes, which allow team members to provide feedback, identify potential issues, and ensure adherence to coding standards before changes are applied to the infrastructure.
The basis of change management is to ensure that all changes go through Terraform. You can explore implementing centralized auditing and implementing policy-as-code to manage change at scale.
Enhancing and maintaining the security of Terraform-managed infrastructure becomes an issue when multiple teams are involved, with frequent updates to Terraform modules and live configurations. Static code analysis tools such as Checkov, tfsec, or Terrascan can be used as part of the workflow.
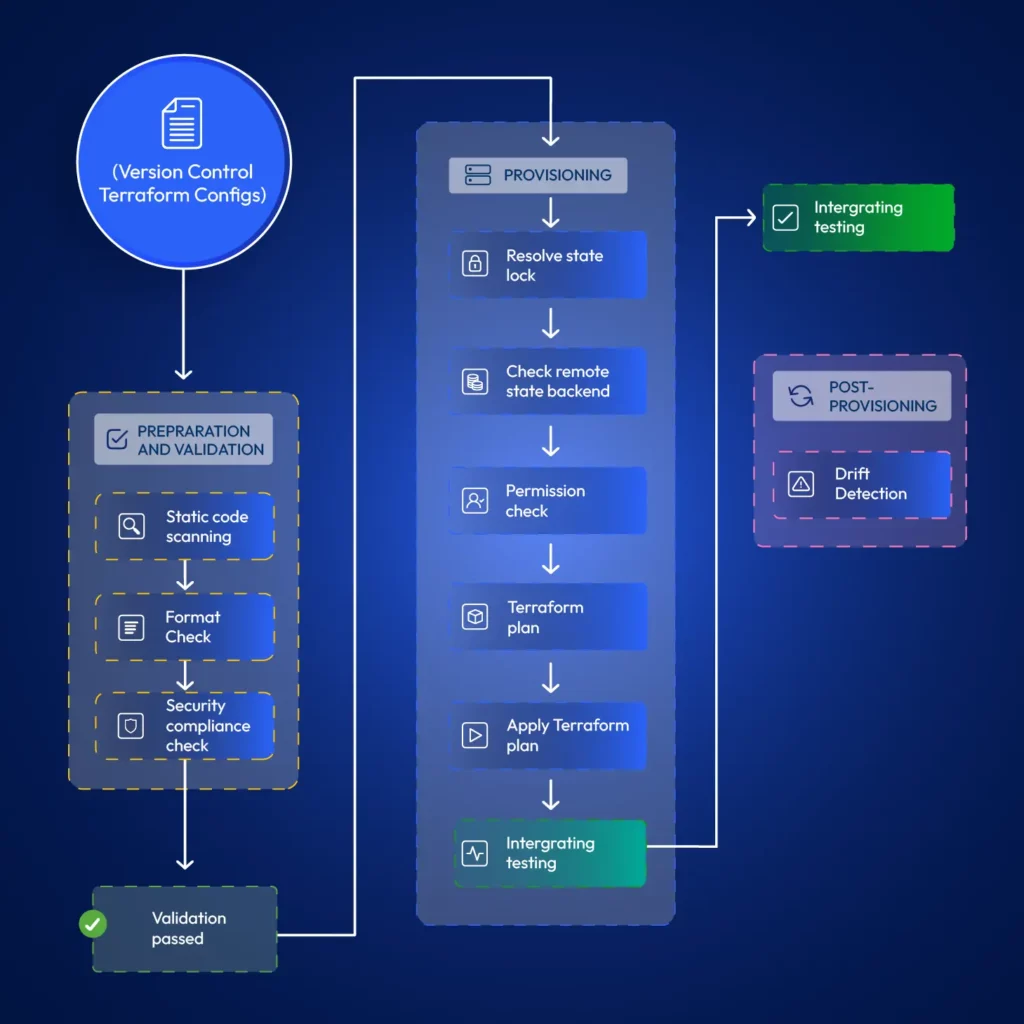
Using Pipelines to Automate Terraform at Scale
It is typical for developers to test Terraform modules locally. However, when promoting changes to live environments, it is best practice if the developer’s duty ends at merging code to the relevant git branch. Automation for terraform provisioning can resolve issues around state locks, permission issues, faster provisioning (cached modules) and allow implementing stages such as static code scanning, format checks, drift detection, etc. Also, pipelines retain a log that teams can refer to later, allowing them to discover when exactly some changes happened.
3 Best Practices for Distributed Teams – Tips for managing infrastructure with geo-scattered teams.
Communication and Collaboration
Clear and documented communication channels are important for distributed teams working with Terraform. Teams should define protocols for infrastructure-related discussions, updates, and issue resolution, ensuring all members know about changes and potential impacts. There can be two levels of communication. When working on internal developments, teams can use channels such as Slack, Teams, or other communication tools the organization uses. However, these channels are unsuitable for change management.
Change management is critical. When promoting changes to live environments, distributed teams should choose a time window with minimal impact on the business and maintain a mechanism to approve and track those changes. Teams generally use tools such as ServiceNow for this purpose.
Standardization
You can achieve standardization by using consistent coding styles and naming conventions across all Terraform configurations. Doing so improves readability, maintainability, and collaboration within distributed teams. Organizations need to enforce using standardized Terraform modules from a private registry ensuring that infrastructure components are deployed in a consistent and compliant manner. Tools such as AWS Config can help you enforce rules on cloud infrastructure if you are using Terraform with AWS.
Version Control
Terraform configurations should be stored in version control, and it should be maintained as the reference to the actual infrastructure. This allows for tracking changes over time, collaborating effectively through branching and merging, and enabling easy rollbacks to previous configurations if necessary. There is no way to version control infrastructure itself, except for resources such as AWS Task Definitions or Launch Templates if using Terraform in AWS environments. Version control is limited to IaC only, not the actual infrastructure.
Security and Access Control in Terraform Workflows – Managing permissions and secrets.
Least Privilege
Least privilege in Terraform Workflows involves granting only the necessary permissions to users, teams, and automation processes required to provision and manage infrastructure resources. When using Terraform with AWS, teams can use IAM roles with scoped permissions instead of credentials.
Secure Handling of API Keys and Credentials
Teams should never include passwords, secrets, or other sensitive data in Terraform code. They may appear in the state file, so make sure that the state file is not readable by unauthorized personnel. Terraform can integrate with dedicated secrets management tools like AWS Secrets Manager.
If using Terraform in AWS, you can retrieve secrets using a data block;
data "aws_secretsmanager_secret_version" "api_key" {
secret_id = aws_secretsmanager_secret.api_key_secret.id
}Policy Enforcement as Code
You can implement policy enforcement as code within your Terraform workflows. For example, when using Terraform in AWS environments, you may want to ensure that you add mandatory tags to all resources you create in your Terraform configurations. You can use policy-as-code tools such as Open Policy Agent (OPA) to define and enforce security and compliance rules. These tools allow you to define and enforce organizational rules for security and compliance across all Terraform configurations.
Limit Direct Access and Enforce Code Reviews
In any organization using DevOps, teams utilize R&D environments for development and separate live environments (dev, staging, and prod) for customer applications. Changes to R&D environments can be made without peer reviews. Developers will have more permissions in R&D environments. This includes permissions to modify infrastructure directly through a cloud console or CLI.
However, peer reviews should be mandatory for all infrastructure code changes in live environments. All changes to live environments should happen only through Terraform.
Monitor and Audit Practices to Scale Terraform for Compliance
Distributed DevOps teams must ensure compliance, track resource deployments, and troubleshoot issues effectively. This requires governance and visibility over infrastructure.
Teams can vaguely track infrastructure changes using cloud-built tools like CloudTrail in AWS. If using Terraform with AWS, you can configure CloudWatch for applicable resources through Terraform itself. However, multi-cloud monitoring platforms such as DataDog can reduce manual configurations and help distributed teams gain end-to-end visibility into their infrastructure. Setting up alerts for critical infrastructure changes, security-related events, and potential compliance violations is good practice.
Another vital aspect is saving Terraform run logs. If you have CI/CD configured, you can use the logs from CI/CD tool for this purpose. You can evaluate platform features such as run history and audit logs if you’re considering automation platforms to manage Terraform provisioning.
Conclusion: How to Scale Terraform for Distributed DevOps Teams
Terraform as an IaC tool requires thoughtful implementation with best practices in mind for infrastructure management within distributed DevOps teams. Terraform comes packed with features required to configure it in a way that promotes collaboration across geo-separated teams. Proper configuration of terraform with AWS or other cloud providers is required to ensure that infrastructure management becomes a competitive advantage rather than a logistical challenge. Terraform is a tool, but using end-to-end solutions such as ControlMonkey can help organizations operate distributed DevOps teams at scale while automatically incorporating all the best practices and advanced features such as drift detection, compliance enforcement and access control baked in.
If you’re scaling Terraform across distributed DevOps teams, ControlMonkey can help streamline operations, enforce compliance, and simplify collaboration without added overhead.

A 30-min meeting will save your team 1000s of hours
A 30-min meeting will save your team 1000s of hours
Author