Today, productivity is a key priority for software engineering teams. Every software development, DevOps and cloud team wants to ensure they are working as productively, efficiently and cost effectively as possible. However, teams frequently get bogged down with manual, repetitive tasks, firefighting to keep the lights on, which impacts their ability to move the needle for the organization on technology innovation.
In the DevOps and R&D world, this term is frequently referred to as engineering toil – the bottleneck that DevOps teams are constantly fighting against. This article examines what engineering toil is, why it happens and what actions your DevOps team can put in place to help eliminate excess toil.
Why Scale and Velocity are Challenging to DevOps?
Right now, the scale and velocity of software development present an enormous challenge for enterprises, with software being built faster than it can be secured. In parallel, organizations expect new infrastructure and cloud workloads to be spun up just as quickly, often with little or no cloud governance around them. However, the reality is that the more mature the cloud environment, the more cloud accounts are added, and as configurations evolve, the environment becomes more complex.
This leads to bloated clouds with risk accumulating, which is not only difficult to manage but inefficient and exposes the organization to increasing security incidents. This has been made worse with the advent of AI-powered development, which has raised the stakes. AI is already accelerating software delivery. This means more code, more changes, more infrastructure to support it and if you’re still relying on manual processes to manage your environment, AI just adds fuel to the fire.

How Engineering Toil Impacts DevOps Productivity
This scenario often leads to excessive engineering toil. Far from simply being irritating, there is growing evidence that the impact of engineering toil in today’s high-stakes, high-velocity cloud environments isn’t just annoying, it is incredibly expensive. It also eats up valuable engineering time, slows down delivery, impacts productivity, puts a blocker on innovation and impacts the ability for the business to create a competitive advantage.
But toil is common throughout most programming and DevOps positions, whether we like it or not. And when it comes to platform engineering, the chances of encountering toil are high. You can think of toil as those tedious workarounds that should be automated but rarely are. This could be due to a lack of standard configurations for deployments, meaning engineers must copy and paste data from one module to another, or it could be an integration that has not yet been automated.
Less Than 50% of an Engineer’s Time Should Be Spent on Toil
According to Google’s SRE Book, which defines toil as manual, repetitive, automatable work that scales linearly, it advocates that organizations should strive to keep toil well below 50% of an engineer’s time. It emphasizes automation and strategic engineering practices to reduce toil. Explore the chapter on eliminating toil.
Additionally, a LeadDev article highlights how unchecked toil can lead to burnout, errors, low morale and career stagnation, with employees voting with their feet. If the DevOps engineers who created your infrastructure leave, your corporate knowledge and experience walk out the door with them.
Engineers have different limits for how much toil they can tolerate, but everyone has a limit. Too much toil leads to burnout, boredom, and discontent. This article advocates that the way to eliminate toil is through automation and/or system redesign.
Furthermore, a recent Eindhoven University of Technology academic paper titled: Toil in Organizations That Run Production Services found that toil is more nuanced than Google’s definition and the challenges in reducing toil include cultural inertia combined with a lack of time to automate. But the paper emphasizes that a concerted effort to reduce toil will yield positive outcomes for both individuals and organizations.
In summary, the research found that what machines should be doing is being done manually and if you’re running cloud infrastructure at scale without a purpose-built automation platform, then toil will just continue to escalate.
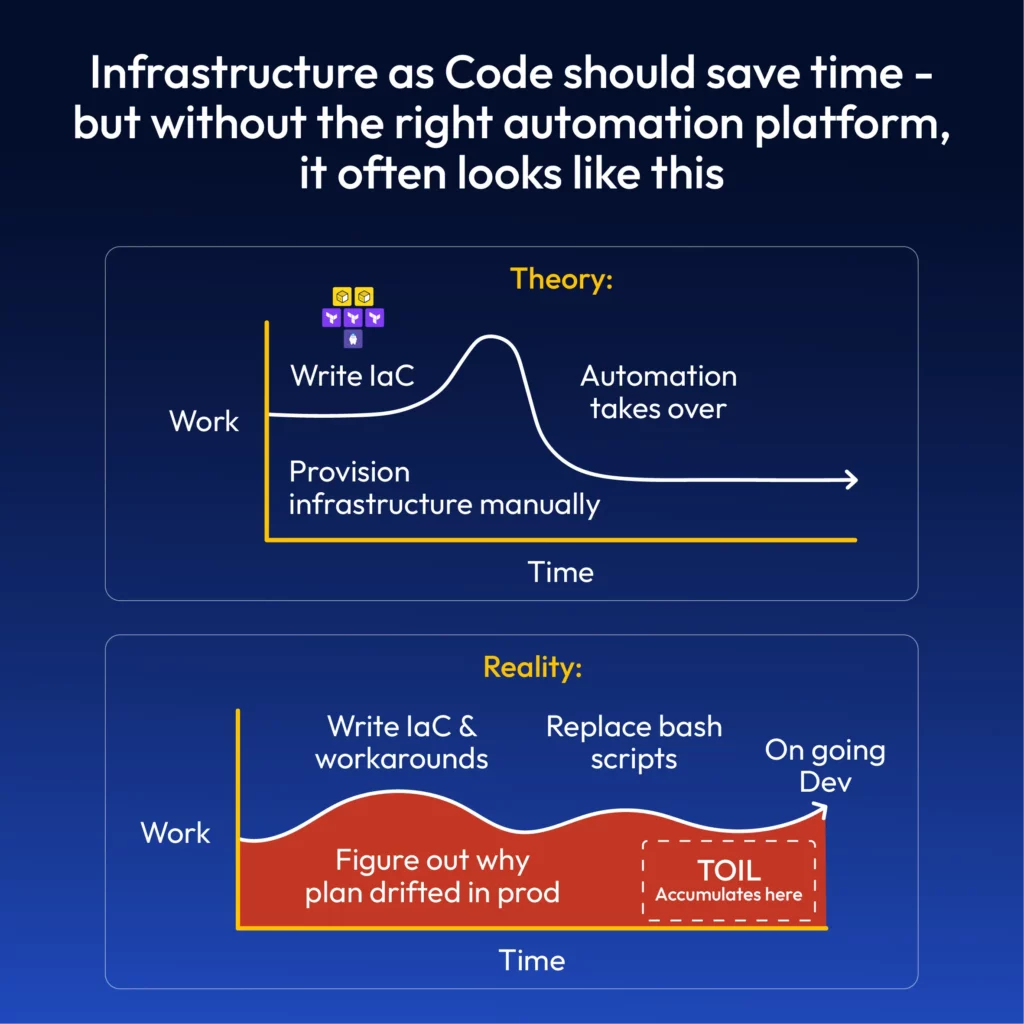
Importance of Prioritizing Long-Term Engineering Projects
The good news is that toil is measurable, and this is where surveys and ticket metrics can help to quantify it. Reducing toil requires engineering effort with automation and system improvements whereby teams prioritize long-term engineering projects over reactive, repetitive tasks.
However, it is important to recognize that not all toil is bad. Small amounts can be tolerable and even satisfying for your engineers, predictable and repetitive tasks can produce a sense of accomplishment and quick wins. They can be low-risk and low-stress activities. Some people gravitate toward tasks involving toil and may even enjoy that type of work. But be warned, excess toil is harmful – it impacts productivity and velocity.
This Google cloud blog offers some practical steps for identifying, measuring, and reducing toil. In particular, it encourages using Infrastructure as Code (IaC) and automation as key strategies.
How Infrastructure as Code (IaC) Helps Reduce Engineering Toil
Infrastructure as Code (IaC) is a powerful tool in the fight against engineering toil. By allowing infrastructure to be defined, provisioned, and managed through code, this enables better cloud control. But layered onto this, engineering teams need automation, and this is where platforms like Terraform enable DevOps to define, provision, and manage cloud and on-prem resources using declarative configuration. In effect, Terraform transforms manual, repetitive tasks into automated, scalable processes using machine-readable configuration files to define infrastructure (servers, networks, databases), automate provisioning and configuration and enable version control and repeatability.
Here’s how IaC directly tackles the characteristics of toil:
| Toil Trait | How IaC Helps |
|---|---|
| Manual | Automates the setup and configuration of infrastructure |
| Repetitive | Scripts can be reused across environments and deployments |
| Automatable | IaC is inherently automatable, you run once, apply anywhere |
| Tactical | Shifts focus from reactive fixes to proactive system design |
| No enduring value | IaC creates reusable templates that add long-term value |
| Scales linearly | IaC enables scalable infrastructure without increasing manual effort |
The benefits of Using IaC to Eliminate Toil
There are several key benefits of using IaC to eliminate toil and these include:
- Consistency: Eliminates “it works on my machine” issues by standardizing environments.
- Speed: Rapid provisioning and updates reduce downtime and manual effort.
- Reliability: Reduces human error and improves system stability.
- Version Control: Infrastructure changes are tracked and auditable.
- Self-healing Systems: Can be integrated with monitoring to auto-remediate issues.
Tackling Toil in Terraform and Cloud Workflows
So, if you are ready to tackle toil, here is a list of common engineering toil issues found in Terraform and cloud workflows, such as:
- Manually running Terraform Plan to preview changes before applying them
- Approving and tracking changes in Slack or spreadsheets
- Debugging cloud drift without full visibility
- Writing custom scripts to enforce policies
- Manually provisioning a VM
- Reviewing code for basic issues, such as open S3 buckets and bad IAM roles
- Your SREs are swamped with “can you deploy this?” tickets.
While each task might not sound that onerous, if you multiply each of these by every developer, in every environment, every week, it is easy to see how arduous toil can become.
Why Toil Often Goes Unnoticed
So why does toil frequently go unnoticed, even if you are using Terraform? If you have a patchwork of GitHub repositories, Jenkins jobs, in-house scripts, and Slack approvals, unfortunately, this isn’t an end-to-end platform, it’s a mismatch of tools and it’s where toil lives and multiplies. As a result, most teams don’t even realize how much toil they’re carrying. Toil creeps in quietly. But it scales quickly.
How ControlMonkey Eliminates Engineering Toil
ControlMonkey was built to erase engineering toil from the Terraform workflow. It’s the only complete solution for end-to-end Terraform automation, allowing DevOps to manage cloud infrastructure with the same confidence that they manage software delivery.
Terraform Automation, ReimaginedIt enables the delivery of self-service deployments. PR-based workflows. Policy enforcement is baked in. There are no custom scripts, no friction, and thereby enabling fast infrastructure provisioning without DevOps bottlenecks. ControlMonkey:
- Auto-runs plans and applies with approval gates
- Enables templatized environments via QualityGates
- Imports legacy resources into Terraform in seconds
Cloud Drift is Eliminated. Visibility? Total.Our Cloud vs. Code guarantee detects drift before it becomes a problem – what’s running in your cloud is mirrored in your code, ensuring predictability and:
- Real-time infra snapshots
- Drift alerts with context
- One-click remediation
Governance Without Grit
- Compliance shouldn’t be manual. ControlMonkey enforces organization policies before anything breaks—without slowing anyone down.
- Role-based controls
- Guardrails to prevent misconfigurations
- Audit trails for every change
And unlike homegrown pipelines or partial tools, it all runs on a platform built for Total Cloud Control.
From Engineering Toil to Total Cloud Control
Toil doesn’t scale. And in today’s cloud, neither should your engineering team.
ControlMonkey eliminates Terraform toil by replacing manual workarounds with intelligent automation and proactive governance, giving engineers back their time and your organization back its development velocity.

A 30-min meeting will save your team 1000s of hours
A 30-min meeting will save your team 1000s of hours
Author