Most disaster recovery plans for DevOps fail—not because of data loss, but because critical infrastructure is overlooked. Is your team ready to tackle this hidden risk? You’ve got cloud disaster recovery (DR) data backups, but your servers, networks, or security groups aren’t ready to spin up. Suddenly, you’re facing missed SLAs, reputational damage, and steep costs. Infrastructure today changes so quickly that static DR plans become obsolete: Relying on data snapshots alone leaves a massive hole in your recovery strategy.
Balancing innovation and uptime is non-negotiable for modern DevOps. During a cloud disaster, manual fixes and guesswork can be fatal. DevOps pipelines evolve too fast for outdated runbooks to remain accurate. Furthermore, compliance frameworks like SOC 2 require provable, consistent recovery—and falling short can invite severe penalties.
This blog post will discover why typical backup strategies aren’t enough for cloud and disaster recovery in fast-paced environments. We’ll also identify key DevOps pitfalls and show how to resolve them. Let’s explore how to keep downtime to a minimum, comply with regulations, and shield your business from incomplete DR plans.
Why Infrastructure Is the Missing Link in Cloud Disaster Recovery
Ensuring cloud disaster recovery isn’t about data replication alone. True resilience requires that every component—servers, networks, load balancers, and security settings—be consistently documented, tracked, and restorable.
Even minor oversights can turn into large-scale outages when disaster strikes. Below are some significant challenges DevOps teams often encounter.
Unmanaged and Undocumented Cloud Resources
Teams sometimes create “shadow” environments for testing or internal projects. If these are missing from official inventories, you can’t re-create them during recovery. With no record of configurations, your engineers may scramble to reconstruct key services from memory, driving up recovery time.
Maintaining a centralized resource registry is crucial for visibility, ensuring nothing critical slips through the cracks.
Slow Recovery and Downtime
Fragmented runbooks and scattered documentation can stall cloud-based disaster recovery efforts. Searching multiple knowledge bases for the latest script or code snippet wastes time you don’t have. Meanwhile, customers experience unavailability, revenue drops, and your reputation takes a hit.
Standardizing a single repository for processes and configurations accelerates recovery and reduces confusion.
Loss of Control
In cloud disaster recovery scenarios, environment drift can be disastrous. One environment might have the newest security rules, while another still has outdated policies. Aligning these under pressure, especially across multiple regions, is error-prone.
Enforcing infrastructure as code (IaC) from the start prevents these discrepancies, but only if your team diligently updates IaC files whenever a change occurs.
High Costs
Every minute you’re offline hits your bottom line. Beyond lost sales, you face potential SLA penalties and strain internal resources with emergency fixes.
Over time, a weak cloud disaster recovery strategy takes a bigger financial toll than investing in proper automation and documentation from the outset. Factoring in lost customer trust and additional overhead, it’s clear that DR shortcuts can turn into costly pitfalls.
The following table shows a summary of hidden DR costs:
|
Cost Factor |
Impact on Business |
|
Revenue Loss |
Missed transactions and sales, e.g., Google Cloud’s accidental deletion of pension accounts |
|
SLA Penalties |
Mandatory compensation for clients |
|
Staff Overtime |
Burnout, reduced morale |
| Emergency Consultants |
Expensive, last-minute help |
Why Traditional Cloud Disaster Recovery Strategies Are No Longer Enough
Traditional DR plans emphasize data snapshots while ignoring complex, interdependent components that power modern applications. DevOps involves networking, DNS, CDNs,firewalls, and load balancers across regions—each requiring quick, scripted provisioning for cloud disaster recovery.
You’re left with partial functionality when cloud disaster recovery solutions focus on storage replication alone. Even services for cloud business continuity and disaster recovery might replicate data globally; however, if they don’t rebuild load balancers, firewall rules, or CDNs, users still face downtime.
Regulations also increasingly demand evidence that you can restore entire operations, not just data. Embracing a holistic cloud business continuity and disaster recovery plan ensures you can relaunch your applications swiftly and prove your readiness to auditors.
Optimizing Cloud Disaster Recovery: Best Practices for DevOps Leaders
A reliable cloud disaster recovery program is more than an IT responsibility—it’s a shared effort across DevOps, security, and operations. Leaders must champion policies that keep infrastructure well-structured, run frequent simulations to gauge effectiveness, and nurture a continuous improvement mindset.
This section presents the key areas to address.
Governance & Policy Enforcement
To ensure your cloud disaster recovery plan is bulletproof, embed clear governance measures into your DevOps workflows. Here’s a streamlined approach:
- Define access & tagging standards: Implement role-based access control (RBAC), enforce tagging standards, and set usage policies to ensure only authorized users can spin up resources—minimizing shadow IT risks.
- Align with compliance frameworks: Integrate your policies with standards like SOC 2 to eliminate last-minute compliance scrambles during a disaster.
- Embed guardrails into your pipelines: Incorporate these rules directly into your pipelines to prevent unauthorized changes that could derail recovery efforts.
This structured strategy directly supports disaster recovery by maintaining a secure, compliant, and ready-to-recover infrastructure.
How to Run a DevOps-Ready DR Drill
When disaster recovery drills are executed like a DevOps playbook, they expose hidden vulnerabilities and turn theory into practice. Follow these steps to ensure your simulations deliver actionable insights:
- Pick a scenario: Choose a realistic outage scenario that mirrors your production environment.
- Start a blind test: Launch an unannounced test to simulate emergency conditions and uncover hidden vulnerabilities.
- Analyze the gaps: Review and document every discrepancy—from runbook gaps to overly manual processes—to pinpoint areas for improvement.
- Automate the fix: Implement automation to address identified weaknesses, transforming reactive steps into proactive safeguards.
Cultivate a Resiliency Mindset
Adopting a resilience-first perspective means constantly iterating, testing, and improving your capacity to bounce back. A few simple actions will keep your organization sharp:
- Encourage cross-training so your team doesn’t rely on a single “hero” engineer for DR tasks.
- Keep tabs on emerging cloud disaster recovery vendors and open-source solutions that can streamline failover processes.
- Share lessons from minor incidents with the entire team; these are valuable learning opportunities, not a time to play the blame game.
Best Practices for Infrastructure as Code in Cloud Disaster Recovery
Infrastructure as code brings consistency and repeatability to cloud disaster recovery, reducing the guesswork when you’re forced to rebuild environments under stress. By version-controlling your entire infrastructure configuration, you ensure each resource, dependency, and setting can be reproduced at will.
Another key advantage of using infrastructure as code for disaster recovery is that it eliminates vendor lock-in. The generated code remains fully portable, allowing you to restore your environment using any vendor or mechanism that best suits your needs.
Infrastructure & Code Management
Centralize your IaC code in your Git repository (e.g., GitHub, GitLab, Azure DevOps, Bitbucket) so that you can track every network, VM, and load balancer definition.
Modularity is also key. For a streamlined cloud disaster recovery, modularize your code, separating security, networking, and application layers. This enables you to re-create the needed parts without overhauling the entire stack. Frequent drift detection checks will also help catch errors, ensuring your DR codebase is up-to-date and reliable.
Backup & Recovery Strategies
Automate daily snapshots of your entire cloud configuration by committing your infrastructure as code to your Git repository. This daily commit serves as a real-time snapshot that allows you to map any deleted or modified resources to their corresponding code from previous days.
By re-running these versioned configurations, you can swiftly restore your environment—a vendor-neutral approach that outperforms proprietary solutions that lock you in.
Security & Compliance
During cloud-based disaster recovery, you’ll likely handle privileged operations, such as provisioning VMs, configuring firewalls, and more. Restrict who can perform these tasks and log each operation meticulously.
By incorporating proactive policies into your regular DevOps workflow, you ensure every configuration is compliant from the start. This proactive setup means that when disaster strikes, your recovery blueprint is already secure and audit-ready—eliminating the need for real-time validation under pressure.
Automated Testing & Monitoring
Include DR tests in your CI/CD pipeline, periodically simulating region failovers or losing certain services to mimic real cloud business continuity and disaster recovery scenarios.
Track metrics like recovery time objective (RTO) and recovery point objective (RPO) to see if you’re meeting your targets. Automated alerts and dashboards will highlight performance gaps, giving you time to fix them before a disaster strikes.
Drift Detection & Remediation
For resources managed via IaC, it is crucial that your code accurately mirrors your live environment. Any discrepancies—referred to as “drift”—could result in your recovery process provisioning an infrastructure that differs from the original setup.
Implement robust drift detection and remediation measures. Either reconcile the real-world configuration to match your code or update your code to reflect the actual environment, ensuring your disaster recovery remains precise and reliable.
IaC Coverage
Not every component of your infrastructure is currently managed through IaC. Legacy systems—often created via ClickOps or outdated scripts—can leave critical gaps in your disaster recovery plan.
Prioritize these uncovered resources by importing them into your infrastructure as code. This proactive step guarantees that your entire environment is versioned, backed up, and ready for rapid restoration when disaster strikes.
Enhancing Cloud Disaster Recovery with ControlMonkey
ControlMonkey revolutionizes your approach to disaster recovery by capturing the state of your cloud environment and automatically generating precise IaC. Scanning your infrastructure for daily snapshots creates up-to-date Terraform configurations that reflect every change you make. This means that when an incident occurs, you can roll back to a known good state almost instantly—no guesswork required.
Get Full Coverage
Because the platform scans your entire configuration, you can rest assured that even if you have resources not managed by IaC or that have drifted from their original code, you’ll receive fully validated code that accurately reflects your live environment.
Analyze Past Configurations
ControlMonkey also includes a powerful “time machine” feature that lets you explore your configuration history without restoring snapshots. This advantage empowers you to analyze past changes, compare configurations, and identify issues—all while keeping your current environment intact.
Enjoy 24/7 Monitoring and Self-Healing
But ControlMonkey doesn’t stop at code generation. Its robust drift detection system monitors your cloud resources 24/7. If any changes occur outside your approved configurations, ControlMonkey alerts you immediately and can even auto-remediate to restore consistency. This self-healing capability dramatically reduces the risk of misconfigurations escalating into significant outages.
Facilitate Compliance
ControlMonkey’s intuitive dashboard and detailed reporting also provide complete visibility into your infrastructure changes, helping you stay compliant with industry standards while streamlining your CI/CD pipelines.
Get One-Click Recovery—No Matter Your Cloud Setup
Whether managing AWS, Azure, GCP, or multi-cloud environments, ControlMonkey empowers your team to execute one-click recovery workflows, maintain regulatory compliance, and ensure your entire cloud ecosystem is resilient and ready to recover immediately.
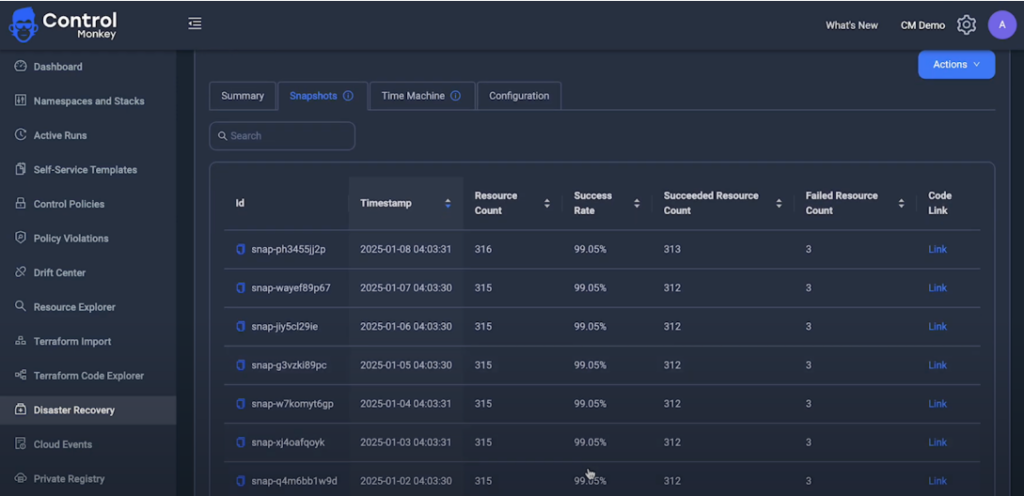
Figure 1: ControlMonkey disaster recovery snapshot
In short, with ControlMonkey, you move from reactive firefighting to proactive management—turning disaster recovery into a seamless, automated process that keeps your business running no matter what challenges arise.
Cloud Disaster Recovery: Conclusion
Neglecting to plan for infrastructure restoration leads to prolonged outages, lost revenue, and eroded brand trust. A comprehensive cloud and disaster recovery framework weaves governance, automation, and regular testing into daily operations. Tools like ControlMonkey refine your DR stance, coupling drift alerts with version-controlled backups so that you can rebuild entire environments fast.
Ultimately, true resilience isn’t merely safeguarding data; it’s about reassembling every piece of your cloud puzzle—no matter how complex—so your users stay connected and your organization continues to thrive, even in the face of the unexpected.
If you’re ready to optimize your cloud disaster recovery plan, consider integrating ControlMonkey for a proactive, automation-first approach.