What Is Cloud Business Continuity and Disaster Recovery?
Cloud adoption is increasing at a rapid rate across all industries. Public cloud spend was more than $675 billion in 2024 with more enterprises moving larger workloads into the cloud – and for good reason. As more enterprises adopt cloud at scale, ensuring cloud business continuity and disaster recovery becomes critical to maintaining uptime and trust, take for example 2025 – Azure an AWS outage.
It is a proven business enabler and offers significant advantages over traditional architecture. As hardware gets older, data center operations become expensive. DevOps teams spend more time managing old systems than creating new solutions.
But once you have migrated to the cloud, You need to keep your cloud running smoothly so daily operations stay on track.
Outages, downtime—even for short periods—cost money, create operational headaches and damage customer relations. This is why a robust cloud business continuity and disaster recovery strategy is essential.
Coupled with a strong DR plan, organizations can ensure cloud-based systems withstand and recover ‘quickly’ from any outages, misconfigurations, human error or cyber attacks.
To remain resilient, companies need to ensure they are ready for every eventuality—not just for if something fails. They must have tried and tested DR plans for their cloud infrastructure.
Downtime Isn’t Just a Technical Problem
Every minute of disruption has cost, reputation and productivity implications:
- Financial losses – For example lost revenue for an e-commerce platform, can be a disaster, even minutes of downtime can result in significant missed sales opportunities.
- Customer dissatisfaction – Downtime can frustrate customers, especially if they rely heavily on the company’s services or products. Imagine not being able to access your network service from your iPhone. This not only damages trust, but can drive customers to competitors.
- Loss of productivity – DevOps teams may be unable to work effectively if critical systems or tools are unavailable. Slow recovery times lead to a drop in productivity, missed SLAs and curtail innovation. Gartner reports that enterprises now dedicate 25% of their annual cloud spend to managing complexity and sprawl
Reputational Damage – Regular incidents harm a business’s brand, affecting customer loyalty, trust and deterring prospective clients. - Operational Chaos – If systems go down unexpectedly, businesses might struggle with uncoordinated responses, delayed workflows and bottlenecks.
- Increased Recovery Costs – Fixing the underlying issues and bringing systems back online can be costly, especially if emergency technical support is needed.
DevOps teams can unintentionally deploy non-compliant infrastructure, especially for those businesses that operate in heavily regulated industries..
This is why a Cloud Business Continuity Plan and DR plan are so important. Because it’s not just about restoring backups—it’s about restoring cloud infrastructure as quickly as possible. However most traditional DR strategies focus on data loss and don’t focus on cloud infrastructure. But manual processes leave gaps, cause cloud drift and increase risk.
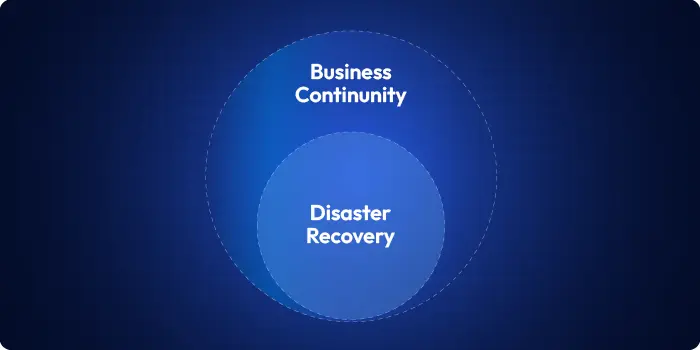
Cloud Disaster recovery planning is a subset of business continuity planning
Gaps in Cloud Resilience
Cloud platforms provide built-in features such as redundancy and fault tolerance to ensure that systems remain operational, even in the face of hardware failures or network disruptions. However, these safeguards don’t address every aspect of operational security management.
DevOps teams are still responsible and accountable for managing the organization’s data, maintaining accurate configurations, and handling change management processes effectively. They must maintain cloud versus code integrity and ensure that what is running in their cloud is mirrored in their code.
But if they’re relying heavily on manual interventions – such as ClickOps – fixes will be slow and lead to inconsistencies, errors, and undocumented changes.
Additionally, infrastructure-as-code (IaC) updates that are neglected or not properly tracked, can result in misconfigurations and cloud drift. Untracked resources—whether unused virtual machines, forgotten cloud allocations, or misconfigured network components—can further compound issues. These not only create gaps in security, performance but are costly to fix. This highlights the importance of real-time monitoring and remediation and infrastructure disaster recovery.
The growing complexity of modern cloud environments makes them hard to manage. Google Cloud’s disaster recovery guide emphasizes the importance of planning for unexpected events to ensure business continuity.
The next section will provide guidelines to strategies for designing robust Cloud DR plans highlighting the need to identify critical systems and the impact these have on the business if they are not available. It recommends testing and refining recovery processes regularly.
Why Cloud Business Continuity and Disaster Recovery Should Never Be an Afterthought
Robust cloud business continuity and DR strategies are integral to cloud resilience. Teams must build them into infrastructure design from the start—not as an afterthought.
DevOps teams must approach infrastructure with the same principles as modern software development—treating it as code that is meticulously versioned, well- governed, and easy to restore when needed. This requires a shift in mindset to:
- Automatically track and fix unintended changes in infrastructure:
- Leveraging monitoring tools like ControlMonkey to detect anomalies and initiate automatic corrections. By taking a snapshot of your cloud infrastructure, everyday, this enables DevOps to easily revert to any previous known good state.
- Creating daily, restorable snapshots of your environment:
- Frequent snapshots provide the ability to recover quickly from disruptions.
- Using policies and guardrails to block risky code before it’s deployed:
- Use automated checks to enforce compliance and block errors before they spread.
- Making rollback a feature, not a panic button:
- Designing rollback processes and features that allow teams to reverse changes swiftly without stress, ensuring instant recovery whenever they need it.
How Block achieved Cloud Business Continuity and Disaster Recovery
Block, a global tech vendor, partnered with AWS and ControlMonkey to implement Infra DR. This gave them the ability to recover from cloud disasters —or even simple issues like accidental resource deletion.
Block did not have consistent automation and tracking for its infrastructure. It also did not know the full extent of its cloud footprint or configurations. This meant that it had no guarantee that its infrastructure was completely covered and this meant that some of it might not be recoverable.
There were resources created years ago that we couldn’t even trace,” said Ben Apprederisse, Platform Technical Lead at Block. “We didn’t know if they were in Git. We didn’t know what had changed—or who changed it. That’s not a good place to be when you’re talking about disaster recovery.”
This isn’t unusual; most DR strategies overlook the critical setup that actually powers apps. That’s where Terraform steps in. It’s not just an automation tool – it’s a critical layer of your resilience strategy.
By codifying infrastructure with Terraform, Block can now rebuild its environment from the ground up—not just restore data.
If configurations break or resources are deleted, Block can instantly roll back to a known-good state.
What ControlMonkey really gave us was first like a full backup. And that is being basically, uh, granted with like matrices. So you could basically see the number of resources that you had and the number of resources that we backup. it give us like the infrastructure as code coverage report, which is probably most, the most interesting one for us. I can come to my boss basically and tell him that -hey, uh, 100% of the, of the cloud is now covered of the cloud is now covered. Of the cloud is now covered.
Building Cloud Business Continuity and Cloud DR Readiness with ControlMonkey
ControlMonkey helps companies embed cloud disaster recovery into their everyday operations.
Instead of relying on manual checks or post-incident cleanup, it monitors infrastructure continuously, takes automated snapshots, and enables instant rollbacks—all while staying aligned with security and compliance policies.
It reduces the burden on DevOps teams while increasing the safety net beneath them.
The Best Time to Prepare Is Before You Need It
It’s not a question of if but when – failing to prepare only makes recovery harder when something does happen. By taking a proactive approach to cloud business continuity and disaster recovery, teams can protect their uptime, maintain trust with stakeholders, and move faster with confidence.
Whether you’re scaling up, managing hybrid environments, or standardizing across teams, the time to rethink your continuity plan is now. As AWS highlights, resilience isn’t a one-time project, it’s an ongoing practice.
Ready to future-proof your infrastructure?
Learn how ControlMonkey enables full-stack cloud business continuity and disaster recovery — Start your free cloud disaster recovery assessment
Update:
- 25.10.25 – AWS Outage update
- 03.11.25 – Writer update, Linking update

A 30-min meeting will save your team 1000s of hours
A 30-min meeting will save your team 1000s of hours
Author